Предел прочности — механическое напряжение, выше которого происходит разрушение материала. Иначе говоря, это пороговая величина, превышая которую механическое напряжение разрушит некое тело из конкретного материала.
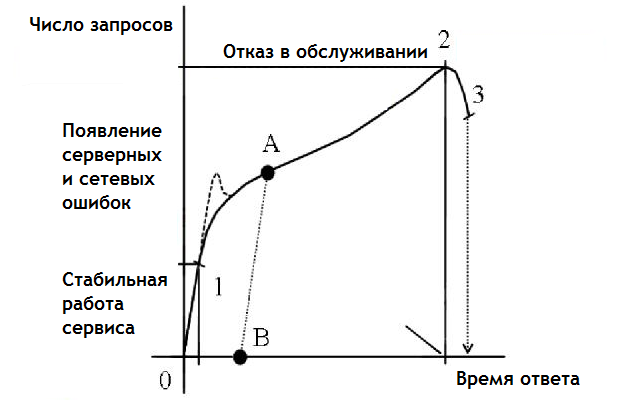
Предел упругости и предел прочности обычно проходят в школьной программе примерно вместе с законом Гука (деформация растет линейно от приложенной силы), подчеркивая область применения этого закона. При работе с большими нагрузками (сотни и тысячи запросов в секунду) модель прочности физических материалов очень хорошо описывает поведение веб-сервиса под нагрузкой и характер его отказа в случае превышения нагрузкой «предела упругости».
В этой заметке мы расскажем, как можно использовать эту модель, чтобы справиться с большой нагрузкой и решить задачу «прогрева» холодного кэша для веб-сервиса (новостного портала, интернет-магазина или SaaS), которую в Айри иногда приходится решать в случае полного сброса кэша сайтов.
«Предел упругости» веб-сервиса
Знание «предела» оптимальной работы веб-сервиса важно при обеспечении его стабильности. Понятно, что в случае DDoS этот предел может быть превышен в десятки, сотни или тысячи раз, но в случае ежедневной посещаемости всплески (уже достаточно большой нагрузки) будут только трех-пятикратными: т. е. достаточно иметь 5-кратный запас «прочности» по посещаемости веб-сервиса, чтобы гарантировать стабильную его работу в 99,9% случаев. Здесь и далее речь идет про дневную посещаемость 100 тысяч посетителей и выше.
Даже если у вас нет пятикратного запаса по прочности, то понимание, где конкретно находится «предел» стабильности, и как после прохождения этого предела сервис будет себя вести, — полезно. Кто осведомлен, тот вооружен.
Как найти этот предел? Он будет характеризоваться двумя особенностями:
- Время ответа сервера после прохождения предела будет расти быстрее, чем до него («сломается» линейность роста времени ответа сервера).
- Появятся сетевые или серверные ошибки (сервер(ы) не будет успевать обрабатывать все запросы).
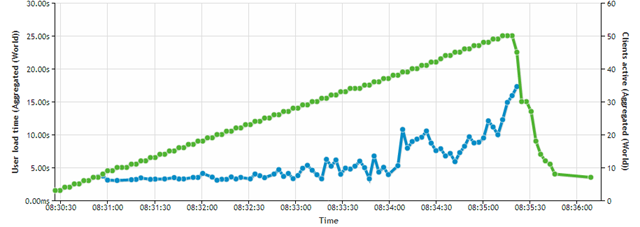
Если у вас сейчас отсутствуют ошибки при работе веб-сервиса, то, скорее всего, вы еще не дошли до этого предела, и стоит воспользоваться любым генератором нагрузки (Яндекс.Танк, JMeter, ab, http_load, LoadImpact или любым другим), чтобы до этого предела дойти. Например, на графике ниже «перегиб» зависимости времени ответа от числа одновременных запросов наступает примерно при 45 запросах в секунду. Если при этом (или при чуть большей нагрузке) начинают возникать ошибки (502, 504, connect timeout) — это и есть искомый предел.
Практическое использование «предела упругости»
В практических целях полученная величина нагрузки (когда веб-сервис еще работает нормально, но при небольшом — порядка 10% — повышении нагрузки уже начинают «заваливаться») может быть использована в следующих целях:
- Рассчитать нагрузку, при которой будет обеспечиваться KPI по времени ответа сервера (например, при 1000 запросов в секунду медианное время будет не больше 200 мс).
- Рассчитать увеличение серверных мощностей, которые будут гарантировать KPI по времени ответа (если сейчас он не достигается) или потребуются при росте нагрузки (например, с 1000 до 1500 запросов в секунду).
- Предупредить ситуации отказа веб-сервиса (если окажется, что ежедневные пики нагрузки уже превышают «предел упругости»): ведь при незначительном превышении нагрузки может произойти полный отказ в обслуживании.
- Получить расчетные значения нагрузки для ситуации «прогрев кэша» (обсудим чуть ниже).
Зная значение «предела упругости» веб-сервиса в случае линейного масштабирования делает работу с высокой нагрузкой полностью прозрачной и предсказуемой, минимизируем риски.
Полезно также знать реальный «предел прочности» веб-сервиса, но по опыту он не превосходит +30% от «предела упругости» (серверы достаточно быстро отказывают из-за лавинообразного роста нагрузки, когда небольшие задержки приводят к увеличение очереди запросов и превышению времени ожидания ответа уже для большинства входящих запросов).
«Прогрев кэша»
Возможна редкая, но очень неприятная ситуация: когда в случае массового обновления записей (страниц) необходимо их все максимально оперативно заменить на новые. Это может быть новый вызов кода, удаление вирусных вставок или исправление технической ошибки. А кэширование сайта позволяет работать в «зоне упругости» и гарантировать линейный рост времени ответа при увеличении нагрузки.
Резкий сброс кэша («прогрев») сразу выводит сайт в зону нестабильной работы или даже за пределы «предела прочности», поэтому недопустим. Существуют два (принципиально схожие) подхода для решения этой задачи.
Первый — это «прогрев» кэширующих серверов по очереди, предполагая, что «прогрев» каждого из них не выводит сайт из «зоны упругости». Характерный график такого «прогрева» показан ниже: число запросов резко возрастает, быстро возвращается к пониженному значению, потом ситуация повторяется до тех пор, пока все кэширующие серверы не будут более-менее «прогреты». Для описания этого процесса в Айри используется термин «Каскадный сброс кэша».
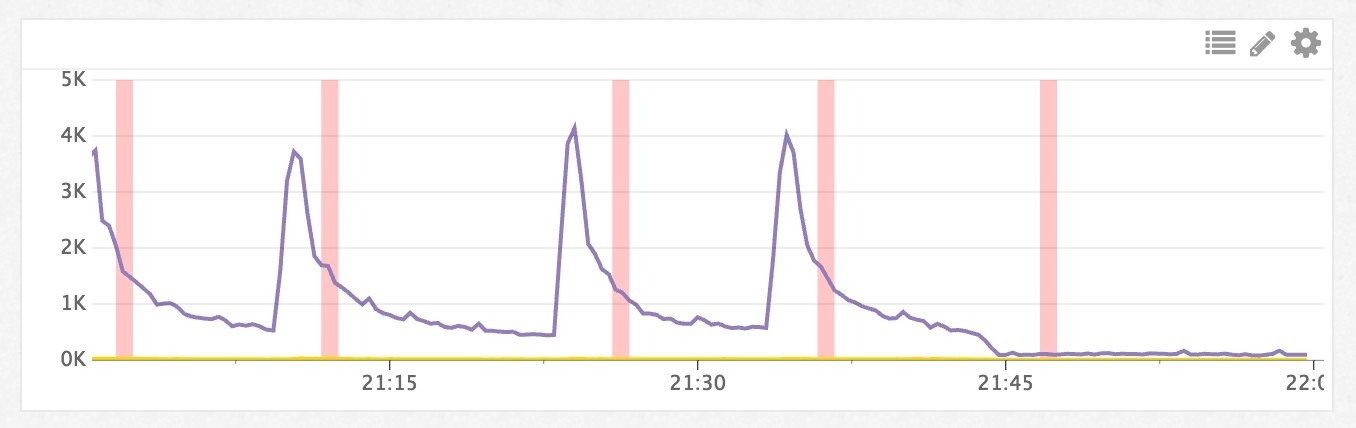
Возможна оптимизация описанного процесса, например, за счет синхронизации кэшей между серверами, в теории, можно добиться меньшего роста нагрузки при «прогреве» очередного сервера. Но на практике либо кэш серверов несколько различается (пересечение кэшей не более 20-30%), поэтому взаимное использование не дает кратковременного эффекта. Либо частота запросов к «прогретым» данным достаточно высока, и «прогрев» нового сервера происходит очень быстро (как на графике выше), поэтому синхронизация не требуется.
Второй подход — это физическое ограничение числа запросов (если они «прогревают» кэш достаточно медленно), чтобы при «прогреве» веб-сервис не выходил из «зоны упругости». В частности, в Mail.ru используют iptables, в Айри.рф используют IP Anycast. В любом случае для большинства пользователей веб-сервис оказывается на некоторое время недоступным, и по мере накопления кэша появляется для все большего числа пользователей (иначе сервис будет недоступен одновременно для всех из-за превышения «предела прочности»).